pub struct SpongeHash256<const R: usize = DEFAULT_PERMUTE_ROUNDS> { /* private fields */ }Expand description
This struct encapsulates the state for a “streaming” (incremental) SpongeHash-AES256 computation.
The const generic parameter R specifies the number of permutation rounds to be performed, which must be a positive value. The default number of permutation rounds is given by DEFAULT_PERMUTE_ROUNDS. Using a greater value slows down the hash calculation, which helps to increase the security in some usage scenarios, e.g., password hashing.
§Usage Example
The easiest way to use the SpongeHash256 structure is as follows:
use hex::encode_to_slice;
use sponge_hash_aes256::{DEFAULT_DIGEST_SIZE, SpongeHash256};
fn main() {
// Create new hash instance
let mut hash = SpongeHash256::default();
// Process message
hash.update(b"The quick brown fox jumps over the lazy dog");
// Retrieve the final digest
let digest = hash.digest::<DEFAULT_DIGEST_SIZE>();
// Encode to hex
let mut hex_buffer = [0u8; 2usize * DEFAULT_DIGEST_SIZE];
encode_to_slice(&digest, &mut hex_buffer).unwrap();
// Print the digest (hex format)
println!("0x{}", core::str::from_utf8(&hex_buffer).unwrap());
}§Context information
Optionally, additional “context” information may be provided via the info parameter:
use sponge_hash_aes256::{DEFAULT_DIGEST_SIZE, SpongeHash256};
fn main() {
// Create new hash instance with “info”
let mut hash: SpongeHash256 = SpongeHash256::with_info("my_application");
/* ... */
}§Important note
The compute() and compute_to_slice() convenience functions may be used as an alternative to working with the SpongeHash256 struct directly. This is especially useful, if all data to be hashed is available at once.
§Algorithm
This section provides additional details about the SpongeHash-AES256 algorithm.
§Internal state
The state has a total size of 384 bits, consisting of three 128-bit blocks, and is initialized to all zeros at the start of the computation. Only the upper 128 bits are directly used for input and output operations, as described below.
§Update function
The “update” function, which absorbs input blocks into the state and squeezes the corresponding output from it, is defined as follows, where input[i] denotes the i-th input block and output[k] the k-th output block:
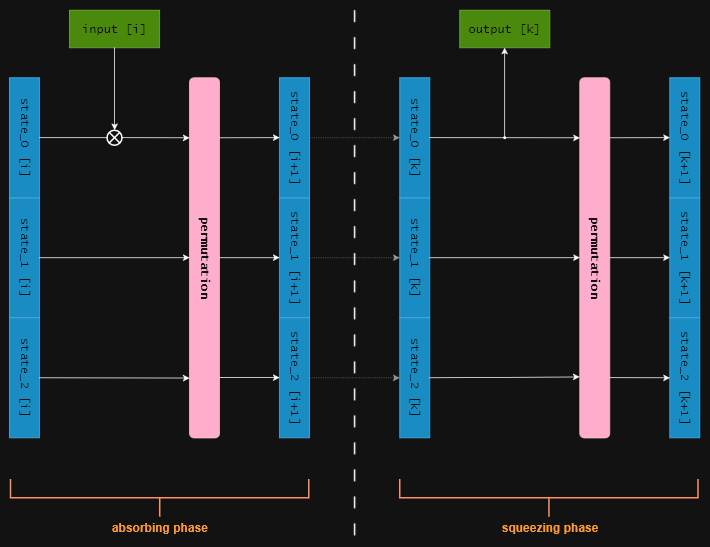
§Permutation function
The “permutation” function, applied to scramble the state after each absorbing or squeezing step, is defined as follows, where AES-256 denotes the ordinary AES block cipher with a key size of 256 bits and a block size of 128 bits.
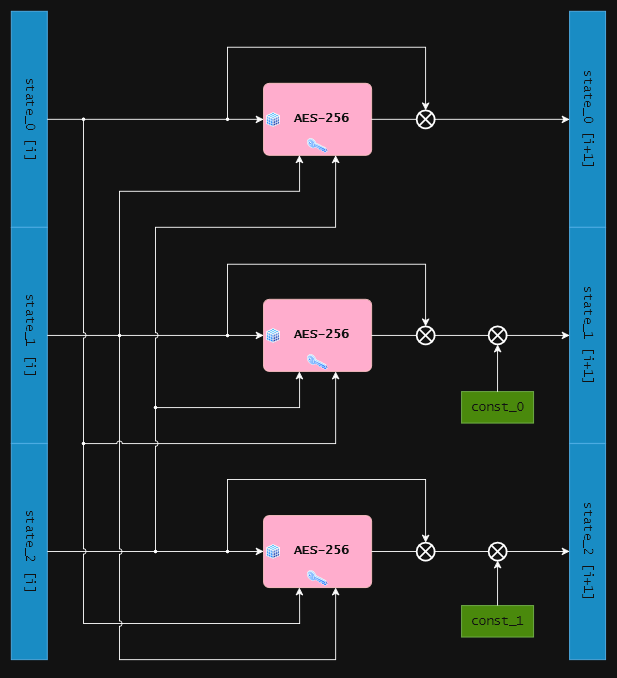
The constants const_0 and const_1 are defined as full blocks filled with 0x5C and 0x36, respectively.
§Finalization
The padding of the final input block is performed by first appending a single 1 bit, followed by the minimal number of 0 bits needed to make the total message length a multiple of the block size.
Following the final input block, a 128-bit block filled entirely with 0x6A bytes is absorbed into the state.
Implementations§
Source§impl<const R: usize> SpongeHash256<R>
impl<const R: usize> SpongeHash256<R>
Sourcepub fn new() -> Self
pub fn new() -> Self
Creates a new SpongeHash-AES256 instance and initializes the hash computation.
Note: This function implies an empty info string.
Sourcepub fn with_info(info: &str) -> Self
pub fn with_info(info: &str) -> Self
Creates a new SpongeHash-AES256 instance and initializes the hash computation with the given info string.
Note: The length of the info string must not exceed a length of 255 characters!
Sourcepub fn update<T: AsRef<[u8]>>(&mut self, chunk: T)
pub fn update<T: AsRef<[u8]>>(&mut self, chunk: T)
Processes the next chunk of the message, as given by the chunk parameter.
A chunk can be of any type that implements the AsRef<[u8]> trait, e.g., &[u8], &str or String.
The internal state of the hash computation is updated by this function.
Sourcepub unsafe fn update_range(&mut self, source: Range<*const u8>)
pub unsafe fn update_range(&mut self, source: Range<*const u8>)
Processes the next chunk of “raw” bytes, as specified by the Range<*const u8> in the source parameter.
The internal state of the hash computation is updated by this function.
§Safety
The caller must ensure that all byte addresses in the range from source.start up to but excluding source.end are valid!
Sourcepub fn digest<const N: usize>(self) -> [u8; N]
pub fn digest<const N: usize>(self) -> [u8; N]
Concludes the hash computation and returns the final digest.
The hash value (digest) of the concatenation of all processed message chunks is returned as an new array of size N.
The returned array is filled completely, generating a hash value (digest) of the appropriate size.
Note: The digest output size N, in bytes, must be a positive value! 🚨
Sourcepub fn digest_to_slice(self, digest_out: &mut [u8])
pub fn digest_to_slice(self, digest_out: &mut [u8])
Concludes the hash computation and returns the final digest.
The hash value (digest) of the concatenation of all processed message chunks is written into the slice digest_out.
The output slice is filled completely, generating a hash value (digest) of the appropriate size.
Note: The specified digest output size, i.e., digest_out.len(), in bytes, must be a positive value! 🚨
Trait Implementations§
Source§impl<const R: usize> Clone for SpongeHash256<R>
impl<const R: usize> Clone for SpongeHash256<R>
Source§fn clone(&self) -> SpongeHash256<R>
fn clone(&self) -> SpongeHash256<R>
1.0.0 (const: unstable) · Source§fn clone_from(&mut self, source: &Self)
fn clone_from(&mut self, source: &Self)
source. Read more